L'apprentissage statistique, également connu sous le nom d'apprentissage automatique (machine learning en anglais), est un domaine de l'informatique et de la statistique qui se concentre sur le développement de techniques permettant aux ordinateurs d'apprendre à partir de données et de prendre des décisions ou de réaliser des prédictions sans être explicitement programmés pour des tâches spécifiques. L'apprentissage statistique est un sous-domaine de l'intelligence artificielle (IA).
Les algorithmes d'apprentissage statistique utilisent des modèles mathématiques et statistiques pour analyser des données, extraire des modèles, et prendre des décisions basées sur ces modèles. Il existe plusieurs types d'apprentissage statistique, notamment :
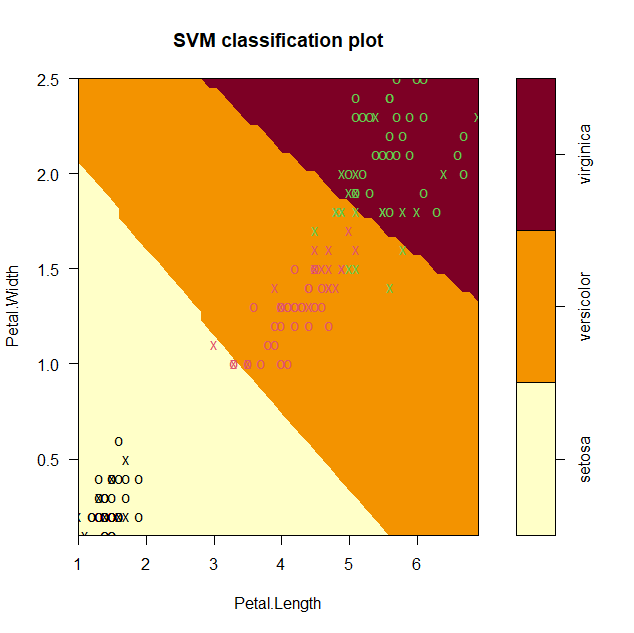
- Apprentissage supervisé : Dans ce cas, l'algorithme est formé sur un ensemble de données d'entraînement qui comprend des exemples étiquetés. L'algorithme apprend à prédire des étiquettes ou des valeurs cibles à partir de nouvelles données non étiquetées. Les exemples incluent la régression (prédire une valeur numérique) et la classification (prédire une catégorie).
- Apprentissage non supervisé : Ici, l'algorithme explore des données non étiquetées pour identifier des structures ou des regroupements. Les exemples incluent la réduction de dimensionnalité (comme l'ACP), la classification non supervisée (comme le regroupement de k-moyennes), et la détection d'anomalies.
- Apprentissage par renforcement : C'est une forme d'apprentissage où un agent interagit avec un environnement et prend des actions pour maximiser une récompense cumulative. Il est couramment utilisé dans des domaines tels que les jeux, la robotique et la prise de décisions automatisées.
L'apprentissage statistique a de nombreuses applications dans le monde réel, allant de la recommandation de produits sur les sites de commerce électronique à la détection de fraudes, en passant par la médecine, la finance, l'automatisation industrielle, et bien plus encore. Il est alimenté par l'énorme quantité de données générées aujourd'hui et est un domaine de recherche en constante évolution.
- معلم: Arsalane Chouaib Guidoum